skynet的cluster集群
集群的使用
现在的游戏服务器框架中,分布式是一种常见的需求。一个游戏服务器组通常可以分成网关服务器、登录服务器、逻辑服务器、跨服服务器等等。
在skynet中,我们可以通过cluster来组建一个集群,实现分布式的部署。
示例
我们先来看一个简单的例子,在这里我们实现了两个skynet结点(进程):一个称为center,一个称为game。
在center中启动一个data服务,然后game结点向center结点的data服务获取数据。
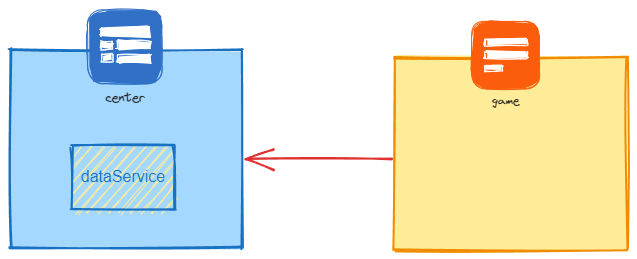
center结点有两个文件centerMain和dataService:
1 | |
1 | |
game结点连接center结点,访问dataService服务:
1 | |
在配置文件中,我们需要指定一个cluster文件:
1 | |
这样一个简单的skynet集群就搭建好了
cluster库
在示例中,我们看到集群的监听和发送,都是通过cluster这个库来操作的。cluster是一个封装的用来进行集群相关操作的函数库,通过local cluster = require("skynet.cluster")引入
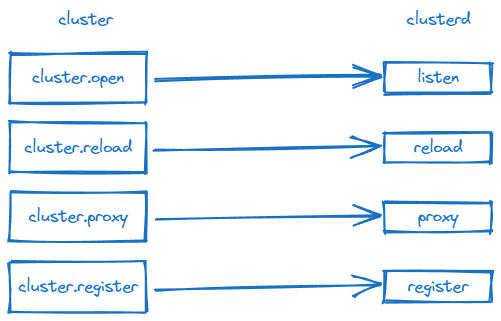
主要的函数有:
1. cluster.reload
cluster.reload用来加载配置。除了通过配置文件之外,我们也可以使用cluster.reload来加载配置:
1 | |
如果不传参数的话,则表示重新从配置文件中加载:
1 | |
reload是新加配置,对于旧的结点,如果没有被覆盖到则没有影响。想要清除旧的结点,可以配置node=nil
可以通过配置节点名字对应的地址为 false 来明确指出这个节点已经下线
2. cluster.open
cluster.open表示监听指定的端口。示例中,在center结点,我们使用cluster.open('center')来监听center端口,在这里是监听127.0.0.1:14880。
这里会发一条listen指令给到clusterd,clusterd启动gate服务,并通过gate服务来监听端口。
clusterd在收到listen时,会启动一个gate服务,所以如果你有自定义的网关服务,最好不要用gate这个服务名。
在一个进程里,我们可以open多个端口,如果其他结点不会主动连接本结点,那也可以不open任何端口。
3. cluster.send / cluster.call
send和call可以向指定的结点发送lua消息。
其效果和在目标结点上,发送lua消息一样。
在game结点上执行:
cluster.send("center", ".dataService", "set", "k1", "v1")
相当于在center结点上执行:
skynet.send(".dataService", "lua", "set", "k1", "v1")
4. cluster.proxy
cluster.proxy用于生成一个代理地址,使发送跨结点的消息看起来和发送本地消息一样:
1 | |
和发送本地消息的区别在于,这种方式下,skynet.send只能支持lua消息。
5. cluster.register / cluster.query
cluster.register用于给某个服务在当前结点注册个名字。
其他结点,则可以使用cluster.query来判断目标结点是否存在某个服务。
clusterd服务
当我们引入cluster库时,会启动一个唯一服务clusterd,这是在cluster.lua文件中,通过skynet.init的方式启动的:
1 | |
cluster库的函数,基本上都是通过发送lua消息到clusterd服务来进行的。
clusterd会处理以下lua消息:
1. reload
clusterd维护一个node_address表,用来记录每个结点对应的IP地址和端口。
2. listen
收到listen消息时,clusterd会启动一个gate服务。然后根据结点名,获取结点地址,启动gate监听网络端口。
当这个gate服务收到网络连接时,会发送lua消息socket到clusterd服务,然后由clusterd启动一个clusteragent服务,来处理这个连接的消息:
1 | |
3. register
clusterd维护一个register_name表,用来记录注册的服务名和地址。
4. proxy
clusterd维护一个proxy表,记录结点名.服务名对应的代理地址,当代理地址不存在时,则创建一个clusterproxy服务。
5. sender
clusterd维护一个node_channel表,记录结点对应的clustersender地址,这里会返回结点对应的clustersender地址,没有则先创建一个。
发送消息到其他结点
cluster.send
cluster.send会通过一个clustersender服务来发送消息。先看看代码:
1 | |
在cluster中维护着sender列表,在同一个服务里,sender记录每个node对应的clustersender服务。
当sender[node]不存在的时候,没有直接创建一个clustersender,而是将当前的参数打包,然后插入到一个task_queue队列中,这是因为创建服务是一个阻塞的过程,在创建服务的过程中,可能会再次调用cluster.send,所以这里将所有创建过程中的参数都缓存起来,等clustersender创建完成后,再统一发送到目标结点。
而创建clustersender,又是发送消息到clusterd服务:local ok, c = pcall(skynet.call, clusterd, "lua", "sender", node)
skynet.packstring可以将多个参数(字符串,数字,表,布尔值)序列化成一个字符串。可以使用skynet.unpack反序列化将参数解出。
cluster.call
cluster.call同样是通过clustersender服务来发送消息。
1 | |
cluster.send使用task_queue可以立刻返回,不会阻塞,而cluster.call本身就是会阻塞的,所以可以直接使用get_sender,以阻塞的形式获取一个clustersender。
注意这里先将参数序列化,等获取到sender之后才重新化序列化,这是因为get_sender这个过程是阻塞的,而参数有可能是个table,在阻塞的过程中,这个table中的值有可能发生变化,导致逻辑不符合预期,所以这里通过序列化来保证发送时的参数不会被改变。
clustersender服务
clustersender用来连接指定结点并发送数据。这个服务是在第一次发送数据时才创建的。
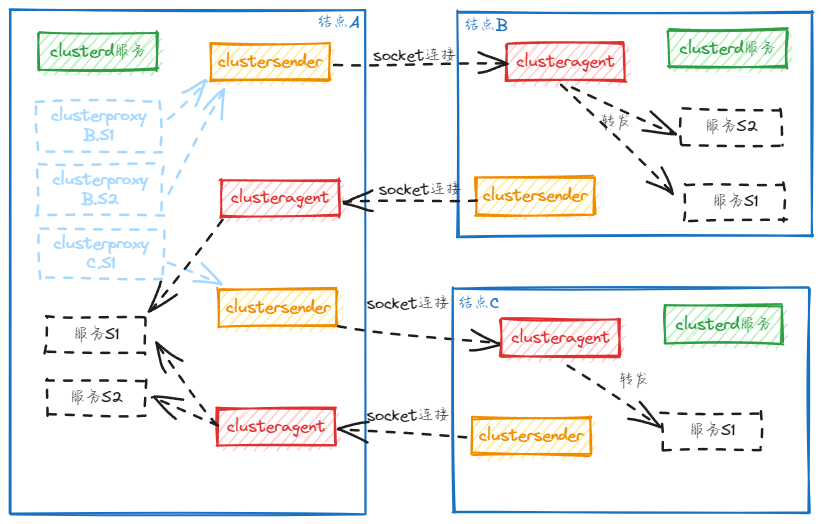
在集群中,结点A向结点B发送过消息,那么结点A就有一个指向结点B的clustersender服务,且只有一个。
clustersender服务是在clusterd服务中创建的,clusterd是一个唯一服务,在这个服务的管理下,每个目标结点只有一个clustersender服务。
现在我们来看看clustersender服务是怎么发送数据的。
启动服务时,我们传过来四个参数
node: 连接的集群的结点名字
nodename: 主机的hostname
init_host: socket连接的地址
init_port: socket连接的端口
在skynet.start时,创建了一个skynet.socketchannel,然后设置lua消息处理函数,这里主要处理两种服务:
push
push对应的是cluster.send,只负责发送,不需要响应。
1 | |
这里的cluster的C层的库,不是lua层的库。
cluster.packpush按特定的协议,来打包数据。
cluster.packpush返回三个值:
request:打包后的二进制数据。
new_session:session+1。
padding:如果数据过大,则将超过单包上限的二进制数据以table数组的形式放在padding里。
channel:request则是将request发送给对端主机,如果有padding,则分多个包发出去。这里第二个参数是response,这里为nil表示不需要响应。
req
req对应的是cluster.call,需要等待响应的返回。
1 | |
command.req调用send_request,返回值如果是table表示这是一个大包切割成多个小包,需要使用cluster.concat连接起来再返回,如果是string则直接返回。
在send_request中,cluster.packrequest和cluster.packpush类似,来打包request类型的数据。
最后同样是交给channel:request来发送socket消息,和push不同的是,这里第二个参数传入了current_session,表示接收响应的会话ID。
这里简单的讲一下channel:request是怎么发送和接收数据的。
channel:request首先会检查当前的连接状态:
- 如果
socket连接还没建立,则先建立连接,再发送数据; - 如果
socket连接已断开,则会抛出异常; - 如果
socket连接正常,则直接发送数据。
在发送数据的时候,如果数据包太大(超过32K),则会切分成多个包来发送。
如果需要等待响应数据,那么会调用socketchannel的__response函数,这个函数是在socketchannel初始化的时候传入的,在socketsender这里,则是read_response函数:
1 | |
read_response中,sock:read是一个阻塞函数,接收对端socket传回来的网络消息。
clsteragent服务
前面提到过,当clustersender第一次发送数据时,会先建立socket连接,而当socket连接建立时,对面的结点会创建一个clusteragent服务,来处理收到的数据。
clusteragent的创建是在clusterd服务中:
1 | |
可以看到,创建clusteragent的时候,传入了三个参数:clusterd地址、source地址(即gate地址)、fd文件描述符(代表这个socket)。
clusteragent在调用skynet.start的时候,设置gate服务的转发,将来自fd的网络消息,都转发到这个clusteragent地址,然后设置了对网络消息的处理:
1 | |
这里的cluster.unpackrequest将clustersender传过来的网络数据进行解析,然后分配给dispatch_request处理:
dispatch_request(_,_,addr, session, msg, sz, padding, is_push)
clustersender中会将服务地址addr打包,这里将addr解析出来,addr可以是字符串,也可以是数字。
当addr是数字0的时候,表示查询某个注册名字的数字地址:
1 | |
当addr是字符串或大于0的数字,则判断addr是不是通过cluster.register注册过的,如果是则addr转化成注册的地址。 然后再根据is_push,来执行skynet.rawcall或skynet.rawsend,进行数据转发。 如果是call,最后还需要将数据通过socket返回给clustersender。
clusterproxy服务
当我们调用cluster.proxy(node, addr)时,会向clusterd申请一个clusterproxy服务。
这里的参数,有三种形式:
- cluster.proxy(“center”, “.data”)
- cluster.proxy(“center.addr”) :等价于 cluster.proxy(“center”, “.data”)
- cluster.proxy(“center@addr”) :等价于 cluster.proxy(“center”, “@data”)
clusterd会以node .. "." .. name作为key,保证同一个key只有一个clusterproxy服务。
而clusterproxy服务很简单:
它会向clusterd申请一个面向node的clustersender,然后就收到的lua消息,转发到这个clustersender上,参数使用服务初始化时的addr。